[chatGPT 시대에서 살아남기] 챗봇 만들기 - #1 챗봇 데이터 수집
[주요 목차]
📊 데이터 수집의 중요성
📁 데이터셋 탐색 및 활용
🧠 딥러닝과 챗봇
🔍 데이터 전처리 과정
💻 구글 코랩 활용법
데이터 수집은 현대 사회에서 정보화의 핵심 요소로 자리잡고 있습니다. 특히 인공지능과 머신러닝 분야에서는 데이터가 알고리즘의 성능을 좌우하는 중요한 역할을 하며, 데이터 수집은 그 시작점입니다. 이번 블로그에서는 데이터를 수집하는 방법과 그 중요성, 그리고 실제 데이터를 활용하여 딥러닝 기반의 챗봇을 개발하는 과정에 대해 알아보겠습니다. 이러한 과정은 단순히 데이터의 양을 넘어, 질 높은 데이터 확보와 전처리의 중요성을 깨닫게 해줍니다. 이를 통해 데이터 과학의 기초부터 심화 과정까지 차근차근 이해할 수 있을 것입니다.
📊 데이터 수집의 중요성
데이터 수집은 모든 데이터 중심 프로젝트의 첫걸음입니다. 특히, 인공지능과 머신러닝 분야에서 데이터는 알고리즘 학습의 근간이 됩니다. 데이터가 부족하거나 부정확하면 알고리즘의 성능은 현저히 떨어질 수밖에 없습니다. 따라서, 데이터의 수집 과정에서 우리는 양질의 데이터를 확보하기 위해 다양한 오픈소스 플랫폼과 데이터셋을 활용해야 합니다. AI 허브와 같은 플랫폼은 이러한 데이터 수집의 훌륭한 도구가 될 수 있습니다. 이러한 플랫폼은 다양한 분야의 데이터를 제공하여, 연구자들이 손쉽게 필요한 데이터를 수집할 수 있도록 돕습니다. 또한, 구글과 같은 검색 엔진을 활용한 데이터 검색 방법도 함께 익혀야 합니다.
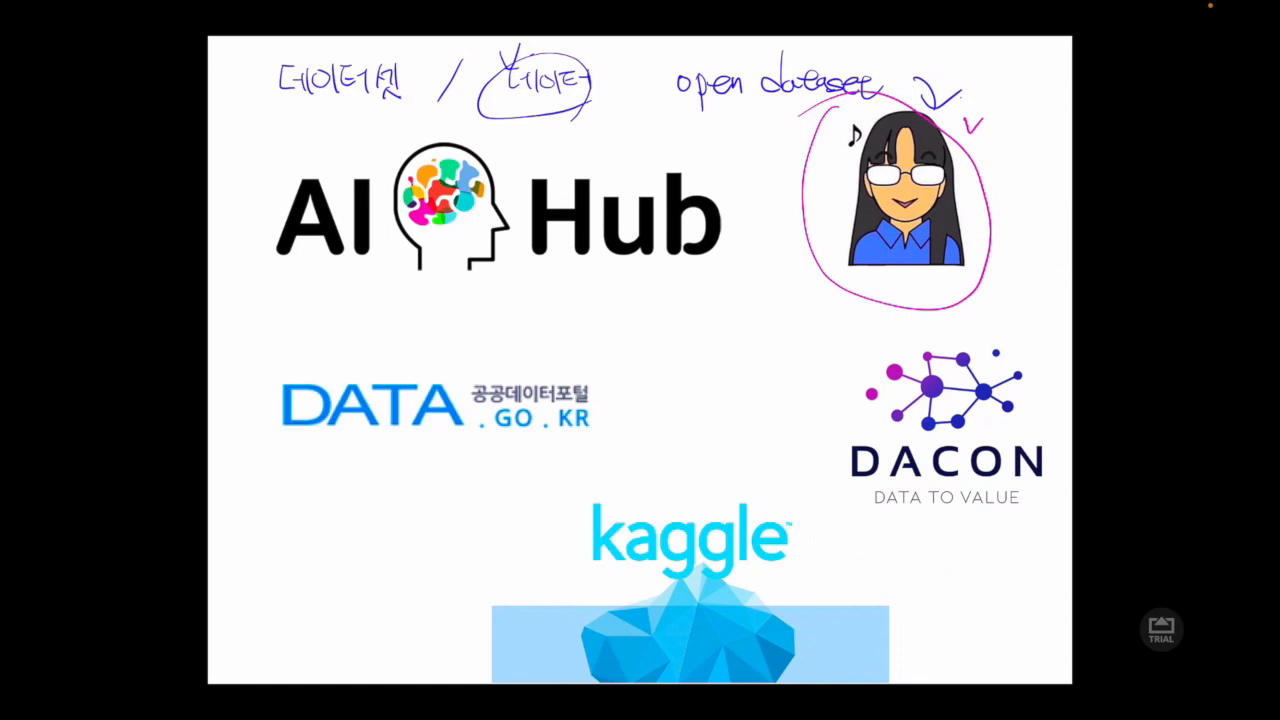
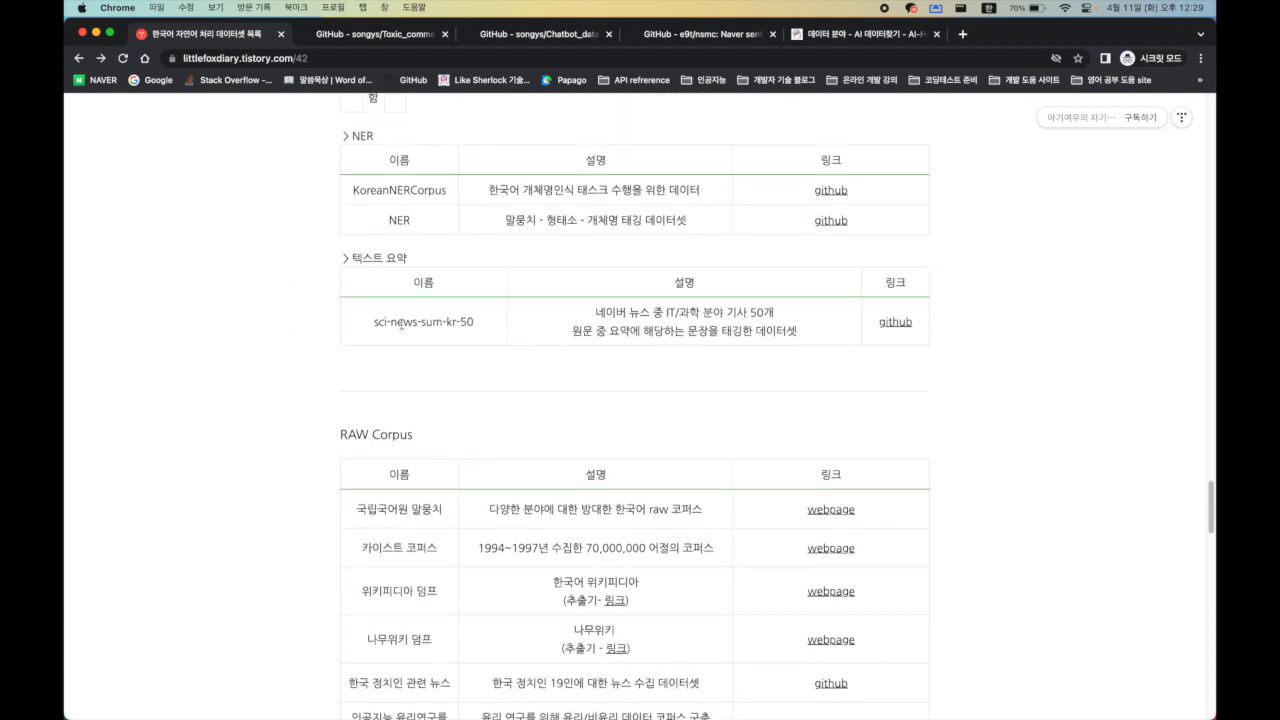
📁 데이터셋 탐색 및 활용
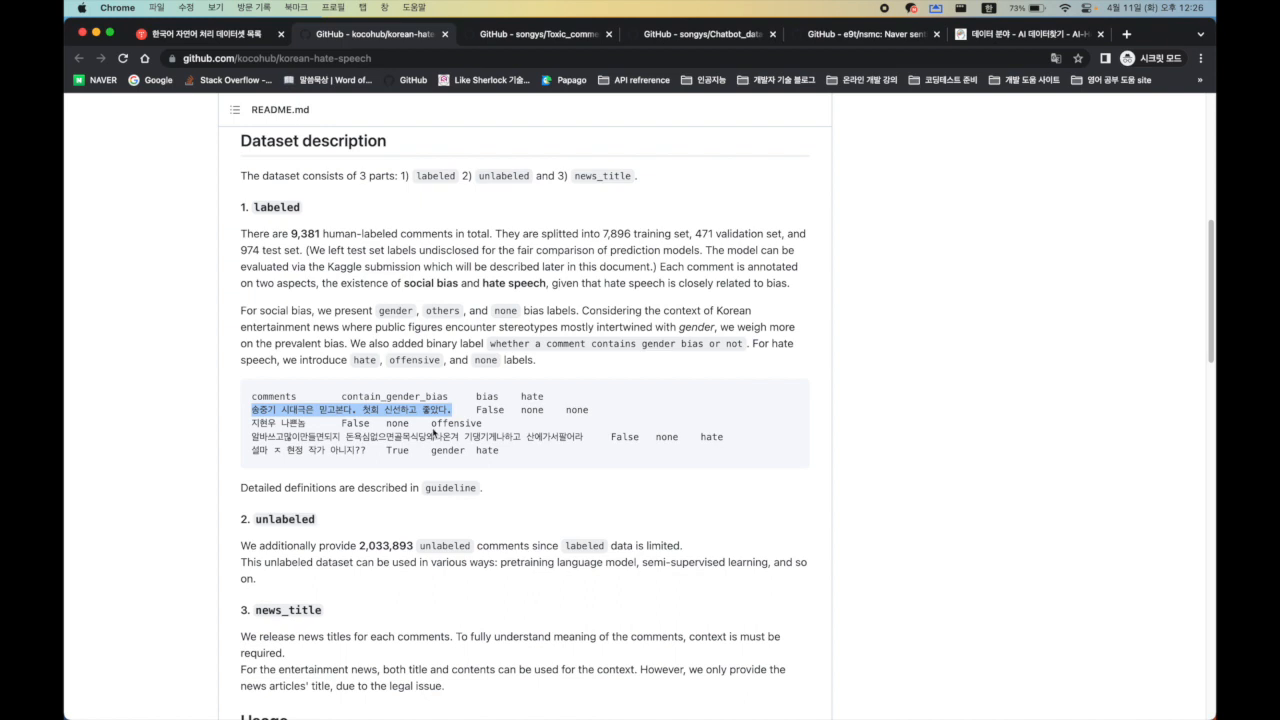
데이터셋 탐색은 수집한 데이터를 이해하고 활용하기 위한 중요한 과정입니다. 특히 챗봇 개발을 위한 데이터셋은 질문과 답변이 명확히 라벨링된 데이터가 필요합니다. 이를 위해 AI 허브와 같은 플랫폼을 통해 일상 대화 데이터, 전문 분야 데이터 등을 탐색할 수 있습니다. 데이터의 출처, 데이터의 양, 데이터의 질을 평가하는 방법을 배우고, 이러한 데이터를 실제 프로젝트에 어떻게 적용할 수 있을지를 고민해야 합니다. 예를 들어, SNS에서 수집된 대화 데이터를 통해 챗봇의 자연어 처리 능력을 향상시킬 수 있습니다.
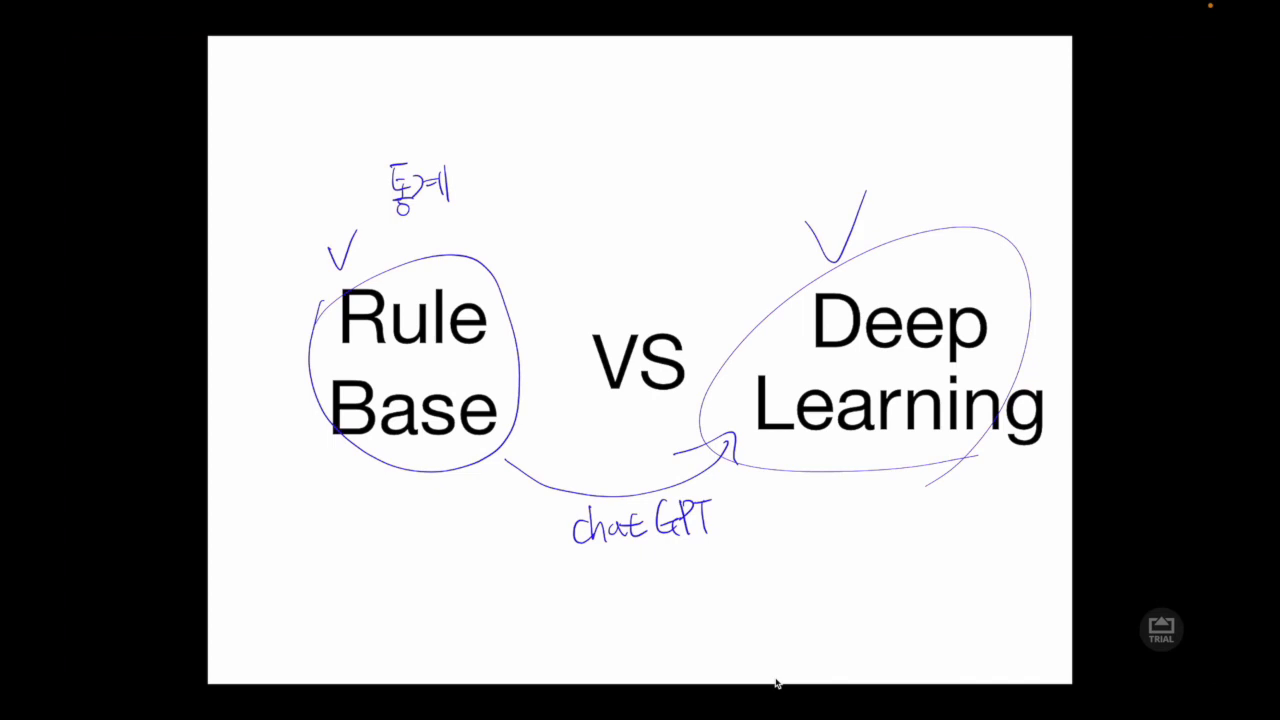
🧠 딥러닝과 챗봇
딥러닝은 챗봇 개발에서 핵심적인 역할을 합니다. 특히 자연어 처리(NLP) 분야에서 딥러닝 알고리즘은 인간과 유사한 대화 능력을 구현하는 데 중요한 역할을 합니다. 챗봇을 개발할 때는 데이터 수집과 전처리 과정을 통해 학습 데이터를 준비해야 합니다. 이후, 이러한 데이터를 딥러닝 모델에 입력하여 학습시키고, 테스트 데이터로 모델의 성능을 평가합니다. 이 과정에서 데이터의 품질과 양이 모델의 성능에 직접적인 영향을 미치며, 이는 딥러닝 모델의 학습 효율성을 결정짓습니다.
🔍 데이터 전처리 과정
데이터 전처리는 수집된 데이터를 분석하기 전 필수적으로 수행해야 하는 단계입니다. 데이터 전처리 과정에서는 데이터의 노이즈 제거, 결측치 처리, 데이터 정규화 등의 작업이 포함됩니다. 이러한 과정은 데이터의 품질을 높여, 모델의 학습과 예측 성능을 향상시킵니다. 특히 챗봇 개발에서는 텍스트 데이터의 전처리가 중요합니다. 불필요한 공백 제거, 특수 문자 제거, 형태소 분석 등을 통해 텍스트 데이터를 정제하는 과정이 필요합니다. 이 과정은 데이터의 의미를 최대한 보존하면서 분석에 적합한 형태로 변환하는 것을 목표로 합니다.
💻 구글 코랩 활용법
구글 코랩은 데이터 분석과 머신러닝 모델 개발에 최적화된 플랫폼입니다. 코랩을 활용하면 별도의 환경 설정 없이 클라우드 기반의 GPU를 활용하여 딥러닝 모델을 개발할 수 있습니다. 데이터셋을 업로드하고, 파이썬 코드를 실행하며, 실시간으로 결과를 확인할 수 있습니다. 특히 대규모 데이터셋을 다룰 때 코랩의 장점이 더욱 부각됩니다. 또한, 코랩에서는 다양한 머신러닝 라이브러리를 쉽게 사용할 수 있어, 챗봇 개발을 위한 모델 학습과 평가를 손쉽게 수행할 수 있습니다.