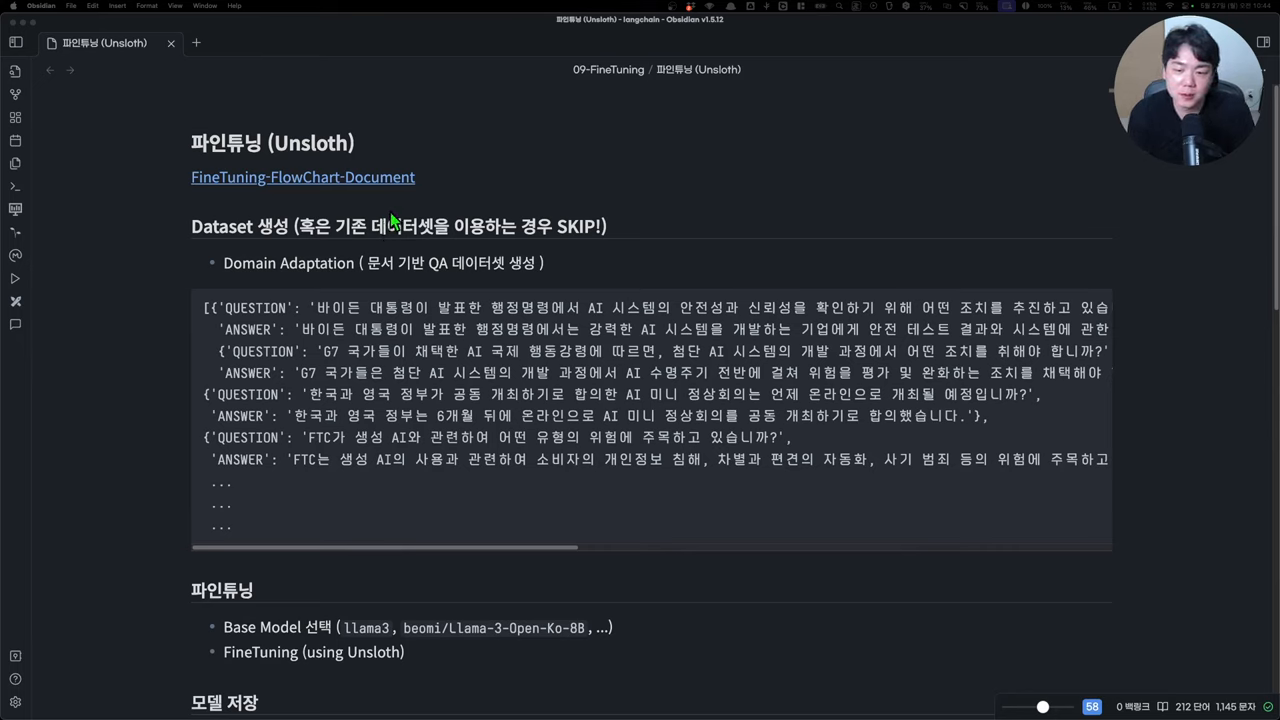
?#파인튜닝? 문서 기반 QA 데이터셋으로 파인튜닝? 진행 후 로컬에서 모델 추론하기
[주요 목차]
목차1 🎯 파인 튜닝의 기본 이해
목차2 🚀 파인 튜닝 프로세스
목차3 📂 데이터셋 준비하기
목차4 🛠️ 모델 튜닝 및 테스트
목차5 🌐 최종 모델 배포
파인 튜닝은 머신러닝과 딥러닝 모델의 성능을 최적화하는 중요한 과정입니다. 최근 인공지능 모델들이 점점 더 복잡해지면서, 특정 도메인이나 작업에 맞춰 모델을 세부적으로 조정하는 파인 튜닝이 큰 주목을 받고 있습니다. 특히, 제한된 데이터셋으로도 효율적인 학습을 가능하게 하고, 모델의 응답 정확도를 높이는 데에 필수적입니다. 이번 블로그에서는 파인 튜닝의 기본 개념부터 시작해 데이터셋 준비, 모델 튜닝, 그리고 최종적으로 모델을 배포하는 과정까지 단계별로 자세히 설명합니다. 이를 통해 독자들은 파인 튜닝을 통해 자신만의 효율적인 인공지능 솔루션을 구축할 수 있을 것입니다.
🎯 파인 튜닝의 기본 이해
파인 튜닝은 사전 학습된 모델을 특정 태스크에 맞추어 세부 조정하는 과정입니다. 이는 기존의 대규모 모델을 활용하여 새로운 데이터를 빠르게 학습할 수 있게 해주는 강력한 도구입니다. 사전 학습된 모델은 이미 다양한 데이터로 학습되어 기본적인 패턴을 이해하고 있지만, 특정한 업무 요구사항에 맞추기 위해서는 추가적인 학습이 필요합니다. 예를 들어, 일반적인 언어 모델은 다양한 주제에 대한 기본적인 이해를 가지고 있지만 특정 도메인, 예를 들어 의료나 법률 관련 질문에 대한 정확한 답변을 위해서는 해당 분야의 데이터로 파인 튜닝이 필요합니다. 이러한 과정은 주로 데이터셋을 준비하고, 모델의 하이퍼파라미터를 조정하며, 원하는 대로 응답을 생성하도록 모델을 훈련하는 단계로 이루어집니다.
🚀 파인 튜닝 프로세스
파인 튜닝의 전반적인 프로세스는 크게 데이터 준비, 모델 선택, 학습 및 평가의 단계로 나눌 수 있습니다. 먼저, 파인 튜닝할 모델의 목적에 맞는 데이터셋을 준비해야 합니다. 이는 모델이 정확한 응답을 생성할 수 있도록 도와줍니다. 그 다음, 사전 학습된 모델을 선택합니다. 최근에는 허깅페이스(Hugging Face)와 같은 플랫폼에서 다양한 사전 학습된 모델을 쉽게 사용할 수 있습니다. 모델을 선택한 후에는 로라(LoRA)나 QLoRA와 같은 기술을 사용하여 모델의 하이퍼파라미터를 조정하고, 새로운 데이터셋에 맞춰 학습시킵니다. 마지막으로, 학습된 모델의 성능을 평가하여 필요시 추가적인 조정을 통해 최적의 성능을 달성할 수 있습니다.

📂 데이터셋 준비하기
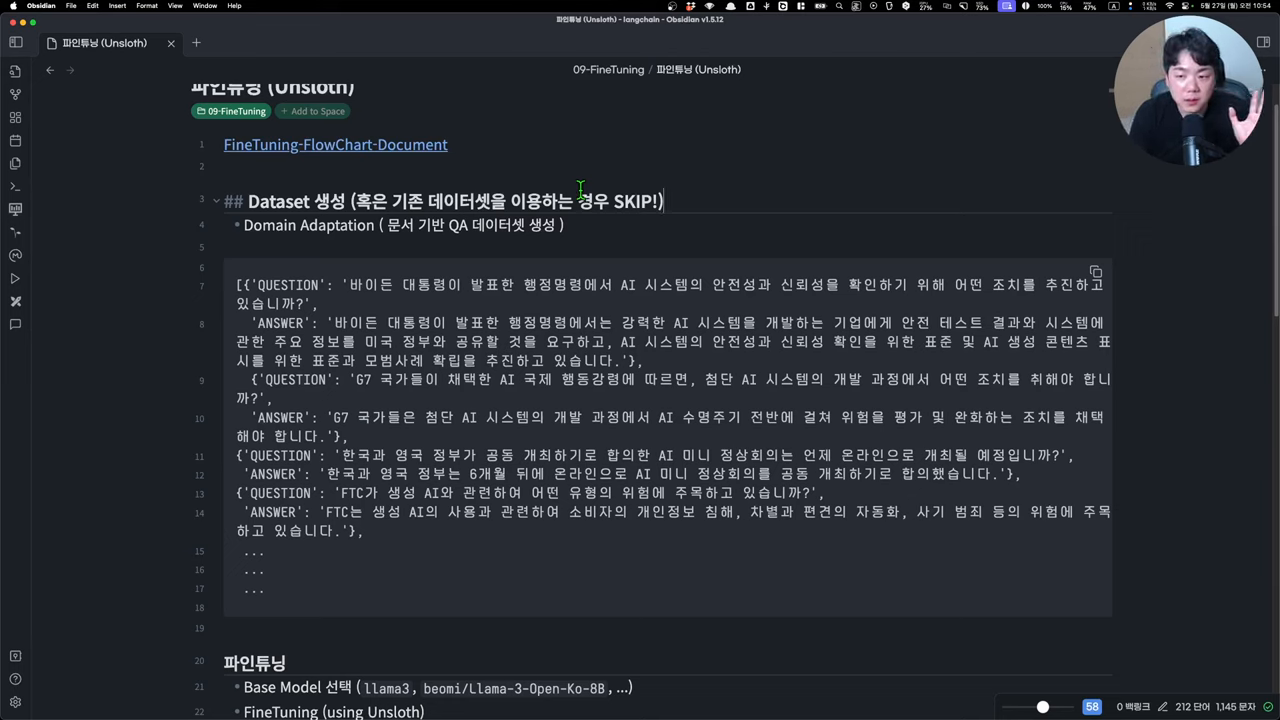
데이터셋 준비는 파인 튜닝의 성공 여부를 결정짓는 중요한 단계입니다. 데이터셋은 모델이 학습할 수 있는 양질의 정보로 구성되어야 하며, 가능한 한 다양한 케이스를 포함해야 합니다. 이를 위해 QA 페어 데이터셋을 구성하거나, 기존의 데이터를 보강하여 사용할 수 있습니다. 데이터셋 준비 시에는 JSON 형식으로 데이터를 저장하는 것이 일반적이며, 이는 모델이 쉽게 학습할 수 있는 형태로 데이터를 구조화하는 데 도움을 줍니다. 또한, 데이터의 질을 높이기 위해 전문가의 검토를 받거나, 기존의 고성능 모델을 활용해 자동으로 QA 페어를 생성하는 방법도 고려할 수 있습니다.
🛠️ 모델 튜닝 및 테스트
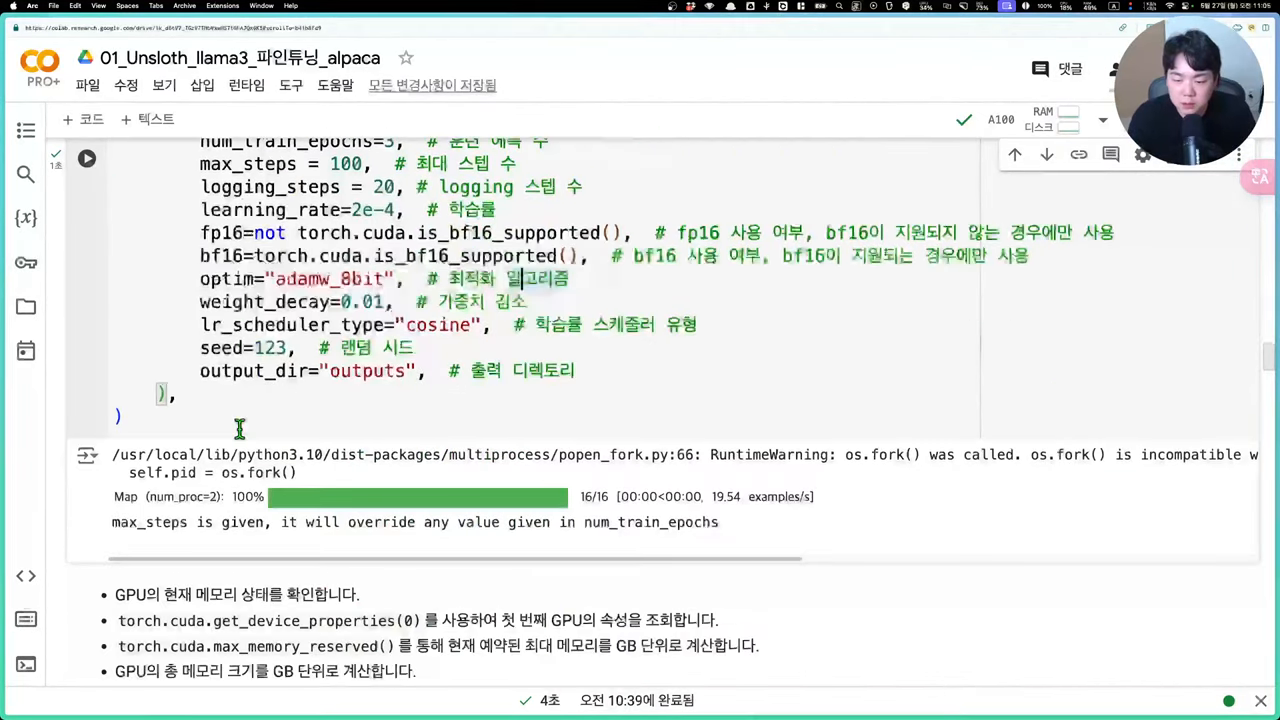
모델 튜닝은 파인 튜닝의 핵심 단계로, 하이퍼파라미터 조정과 학습을 통해 모델의 성능을 극대화합니다. 이를 위해서는 모델의 구조와 학습 방법에 대한 깊은 이해가 필요합니다. 일반적으로 학습률, 배치 크기, 시퀀스 길이 등의 하이퍼파라미터를 조정하며, 이를 통해 모델이 데이터셋에 적합하게 학습할 수 있도록 합니다. 학습이 완료된 후에는 테스트 데이터를 사용하여 모델의 성능을 평가하고, 필요시 추가적인 튜닝을 통해 개선합니다. 이러한 과정은 반복적으로 이루어지며, 최종적으로는 테스트 결과가 만족스러운 수준에 도달할 때까지 지속됩니다.
🌐 최종 모델 배포
파인 튜닝이 완료된 모델은 다양한 방법으로 배포될 수 있습니다. 로컬 시스템에 저장하거나, 허깅페이스와 같은 플랫폼을 통해 공유 및 배포가 가능합니다. 이를 통해 팀원들과의 협업이나 공개 모델로의 활용이 용이해집니다. 또한, GGF 형식으로 변환하여 LM 스튜디오 등에서 직접 사용하거나, 양자화된 모델을 통해 메모리 효율성을 극대화할 수도 있습니다. 최종적으로 배포된 모델은 실제 환경에서의 테스트를 통해 최종 검증 과정을 거치며, 이를 통해 사용자는 보다 신뢰성 있는 인공지능 솔루션을 구축할 수 있습니다.