라마 3.2(Llama 3.2) Vision 모델로 한국어 멀티모달 LLM 만들기 - 한국어 VQA 데이터셋 성능 테스트
|
2025-01-09 12:21
|
조회수 391
#AI모델 #멀티모달 #비전테스트 #인공지능 #텍스트인식 #myip
[주요 목차]
📷 목차1: 라마 3.2 비전 모델 소개
🚀 목차2: 라마 3.2 비전 모델의 주요 특징
🧠 목차3: 멀티모달 모델의 장점
📊 목차4: 라마 3.2 비전 모델의 성능 테스트
🔍 목차5: 라마 3.2 비전 모델의 실용적 활용
인공지능 분야에서 멀티모달 모델은 혁신적인 발전을 이루고 있습니다. 특히 라마 3.2 비전 모델은 텍스트와 이미지를 동시에 처리할 수 있는 능력으로 주목받고 있습니다. 이번 포스트에서는 라마 3.2 비전 모델이 무엇인지, 어떤 특징과 장점을 가지고 있는지, 그리고 실제 성능이 어느 정도인지에 대해 자세히 알아보겠습니다. 이러한 모델이 어떻게 일상생활과 다양한 산업에서 활용될 수 있는지에 대한 통찰도 제공할 것입니다.
📷 목차1: 라마 3.2 비전 모델 소개
라마 3.2 비전 모델은 최신 인공지능 기술을 기반으로 텍스트와 이미지 데이터를 동시에 처리할 수 있는 멀티모달 모델입니다. 이 모델은 기존의 라마 3.1과 비교하여 더욱 향상된 성능을 자랑하며, 다양한 분야에서 활용될 수 있는 가능성을 보여줍니다. 온디바이스 실행이 가능하여, 사용자 환경에서 직접 모델을 운용할 수 있다는 점에서 큰 장점을 가지고 있습니다.
🚀 목차2: 라마 3.2 비전 모델의 주요 특징
라마 3.2 비전 모델의 가장 큰 특징은 텍스트뿐만 아니라 이미지를 입력으로 받아들일 수 있다는 점입니다. 기존의 텍스트 기반 LM과 달리, 이 모델은 이미지와 텍스트를 결합한 형태로 정보를 처리할 수 있어 더욱 다양한 문제를 해결할 수 있습니다. 이러한 멀티모달 능력은 특히 디지털 마케팅, 교육, 의료 등 다양한 분야에서 혁신적인 솔루션을 제공할 수 있습니다.
🧠 목차3: 멀티모달 모델의 장점
멀티모달 모델은 단일 모달보다 훨씬 더 풍부한 정보를 처리할 수 있습니다. 이는 인간이 여러 감각을 통해 정보를 수집하고 이해하는 방식과 유사합니다. 예를 들어, 라마 3.2 비전 모델은 단순히 텍스트로 설명하기 어려운 개념을 시각적 요소와 결합하여 이해할 수 있게 합니다. 이는 교육 및 학습 도구로서의 가능성을 열어주며, 사용자와의 상호작용을 보다 직관적으로 만들어 줍니다.
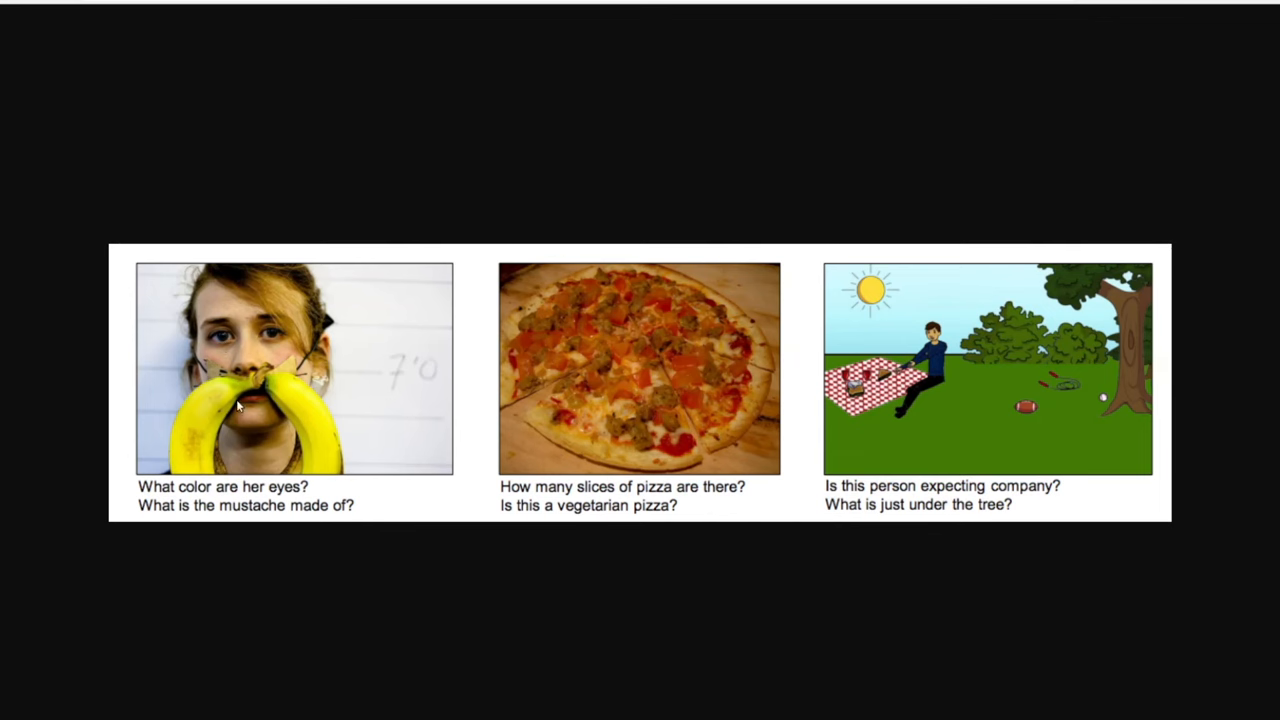
📊 목차4: 라마 3.2 비전 모델의 성능 테스트
라마 3.2 비전 모델은 다양한 벤치마크 테스트를 통해 그 성능을 입증했습니다. 특히 이미지와 관련된 비주얼 퀘스셔닝(VQA) 성능에서 뛰어난 결과를 보여주고 있습니다. 한국어 비주얼 퀘스셔닝 데이터셋을 활용한 테스트에서도, 라마 3.2는 높은 정확도로 이미지 내 정보를 해석하고, 질문에 대한 정확한 답변을 생성할 수 있음을 확인할 수 있었습니다.
🔍 목차5: 라마 3.2 비전 모델의 실용적 활용
라마 3.2 비전 모델은 다양한 산업에서 실용적으로 활용될 수 있습니다. 예를 들어, 인테리어 디자인에서 집안의 사진을 분석하여 스타일을 추천하는 AI 어시스턴트로 활용될 수 있으며, 이미지 번역 어플리케이션에서도 뛰어난 성능을 발휘할 수 있습니다. 이러한 모델을 통해 기업은 고객에게 보다 개인화된 경험을 제공할 수 있으며, 교육 분야에서는 학습자에게 더욱 직관적이고 흥미로운 학습 자료를 제공할 수 있습니다.
🔗 공식사이트
목록
글쓰기